At this point in the series, our build system does everything we wanted it to. Throw a simple source code repository at it and it’ll bring you back an application. Why don’t we call it quits now and move on to better things?
You’re right, we could. But imagine for a second that you’re in the middle of an interview for a post at BigTechCo ®. Suddenly, the interviewer ask you how to scale the build system to billions of files. What do you say? Even worse, you actually managed to pass that interview and now you have to come up with a real solution to the problem. What do you do (besides changing your name and moving to Antarctica)?
Since I care about you and your mental well-being, I’m going to show you a way to attack (and hopefully go medieval on) the problem at hand.
Going Parallel
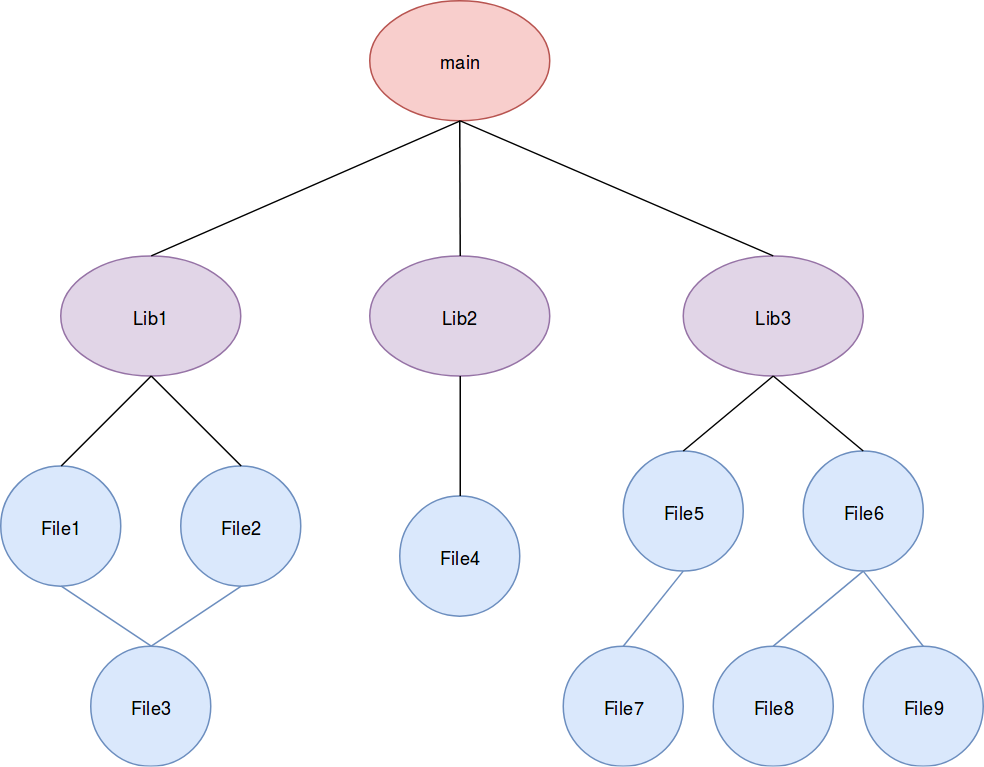
Look at this graph closely. The solution to scale it to infinity and beyond is there. Do you see it?
There is a *censored* load of parallelism in there!
Think about it, all of the outputs that are going to come out of this graph will be generated by one of three functions:
- A function that takes a C++ implementation file and returns an object file
- A function that takes multiple object files and link them into a library file
- A function that takes multiple library files and an application entry point (a main.cpp if you will) and produce an executable.
For the first two functions, the build system will have to invoke them multiple times using multiple data. If you paid any attention to your parallelism classes in university, you should have a vague feeling of déjà vu and the letters SPMD should be floating in the Alpha-Bits soup of your mind. If you didn’t then you need to hand back your diploma and apologize to your teachers.
Design Decisions
It would be easy to say that to scale up we just need to start a thread every time we have some task to do. However, you can’t just start threads like you’d buy candies at the convenience store. Your CPUs (and your pancreas) won’t operate optimally when you throw too much work at them. An oversubscribed core is not a happy core. To mitigate this potential problem, here are two possible solutions:
Solution 1
Start threads, but only at the highest level. In our case, this would mean that we would assign a thread per subgraph.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
bool Compile(const DependencyGraph& graph, const std::string& appName)
{
const DGN& root = graph.GetRoot();
std::vector<std::string> libFiles;
std::vector<std::thread> workers;
// Generating a lib file per subgraph linked to the root node
for(const auto& child : root.GetChildren())
{
workers.emplace_back([child, &libFiles](){
/* Process subgraph */
/* Be careful to use a mutex to access libFiles */
});
}
// Every thread needs to be joined before going further
for(auto& w : workers)
{
if(w.joinable())
{
w.join();
}
}
return LinkToExecutable(libFiles, root.GetFile(), appName);
}
Depending on your machine and the dependency graph at hand, this might still have an oversubscription problem. This leads us to the second solution: using a task-based approach.
Solution 2
Don’t directly start threads. Instead, create tasks that a system will process in a parallel fashion. More often than not, this so-called system will be some sort of thread pool that’ll know best how to make the most of the available threads, leaving you with only having to worry about the jobs you want it to process.
As an example, I’ll be using std::future which is what the C++ standard library offers in terms of task-based parallelism as of C++17 (well not quite really, but this is the best we have while waiting for executors).
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
bool Compile(const DependencyGraph& graph, const std::string& appName)
{
const DGN& root = graph.GetRoot();
std::vector<std::string> libFiles;
std::vector<std::future<void>> workers;
// Generating a lib file per subgraph linked to the root node
for(const auto& child : root.GetChildren())
{
workers.emplace_back(
std::async(
std::launch::async,
[&child, &libFiles](){
/* Process subgraph */
/* Be careful to use a mutex to access libFiles */
});
}
return std::when_all(workers.begin(), workers.end(),
[&libFiles, &root, &appName](auto)
{
return LinkToExecutable(libFiles,
root.GetFile(),
appName);
}).get();
}
What’s really beautiful about this approach is that performance won’t really suffer even if we prefer our tasks to be finer grained. Hence, if you wanted to parallelize the compilation of C++ files to object files and the assembly of a library file, you could implement something similar to this.
Beware there’s recursion involved!!
First, some let’s create some object to hold our compilation logic.
1
std::function<void(const Node&)> childNodeFtor;
We’ll also need something to contain the generated library files.
1
std::vector<std::string> libFiles;
Since we’ll manipulate a collection concurrently, we’ll use a mutex.
1
std::mutex objMutex;
What we want to do now is visit each child of a given node and create a task for each of them. “What will that task entail?” you ask. Visit each child of that node and create a task for each of them. “What will that task entail?”… Alright, I’ll stop here.
More seriously though, we need to do two things for each node.
First, visit its children and process them. Doing so require using recursion. This is why we’ll employ a recursive lambda. Also worth mentioning, this lambda will return a std::vector<std::future<void>>. That way the caller will have something to manipulate if he wants to add a continuation to the processing of the child node.
Second, create an object file out of the C++ file encapsulated by that node once all its children have been dealt with. Again, using std::when_all is the way to go. This is where the fact that we return a std::vector<std::future<void>> will come in handy.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
childNodeFtor = [&objMutex](const Node& node,
std::vector<std::string>& objFiles)
{
std::vector<std::future<void>> childWorkers;
for(const auto& child : node.GetChildren())
{
childWorkers.emplace_back(
std::async(
std::launch::async,
[&child, &objMutex](std::vector<std::string>& objFiles)
{
// We need to process the node's children now
// because they'll be needed to compile the node
auto grandchildWorkers{ childNodeFtor(child) };
// Wait for the children then
std::when_all(
grandchildWorkers.begin(),
grandchildWorkers.end(),
[&objMutex]()
{
std::lock_guard<std::mutex> objLock{objMutex};
const std::wstring& cppFile = child.GetFile();
objFiles.emplace_back(CompileFile(cppFile));
};
}));
}
return childWorkers;
}
All the ingredients have been prepared, so put it in the oven and let it cook.
1
2
3
4
5
6
7
8
9
10
11
12
13
for(const auto& child : root.GetChildren())
{
std::vector<std::string> objFiles;
std::vector<std::future<void>> childWorkers;
childWorkers = childNodeFtor(child, objFiles);
std::when_all(childWorkers.begin(), childWorkers.end(),
[&objFiles, &libFiles]()
{
libFiles.emplace_back(LinkToLibrary(objFiles));
});
}
}
Note that, at the top level, having a std::vector<std::future<void>> returned to us is useful to us because it allow us to assemble library files in a timely fashion.
See, as with the reaper, you don’t have to fear recursion.
Coming up next: What’s more efficient than running all our cores at full throttle?